Unlocking Data With Generative Ai And Rag Pdf

The deluge of unstructured data, particularly in PDF format, has long been a bottleneck for organizations seeking actionable insights. Mountains of reports, contracts, research papers, and internal documents remain locked, their potential largely untapped. But a confluence of advanced technologies – specifically Generative AI and Retrieval-Augmented Generation (RAG) – are poised to revolutionize how we access, understand, and utilize this crucial information.
This article explores how the integration of Generative AI and RAG is unlocking the data trapped within PDFs, empowering businesses to make data-driven decisions, improve efficiency, and gain a competitive edge. We'll examine the underlying technologies, real-world applications, and the potential challenges and opportunities that lie ahead.
Understanding the Power of Generative AI and RAG
At its core, Generative AI refers to a class of artificial intelligence algorithms capable of generating new content, including text, images, and code. Models like GPT-4 and Bard are trained on massive datasets, enabling them to understand and generate human-like text.
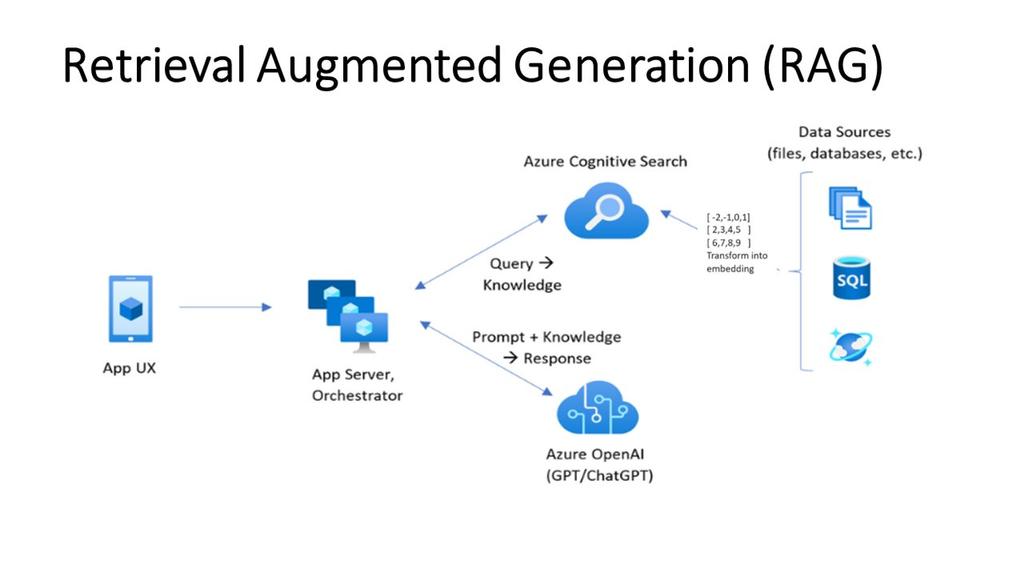
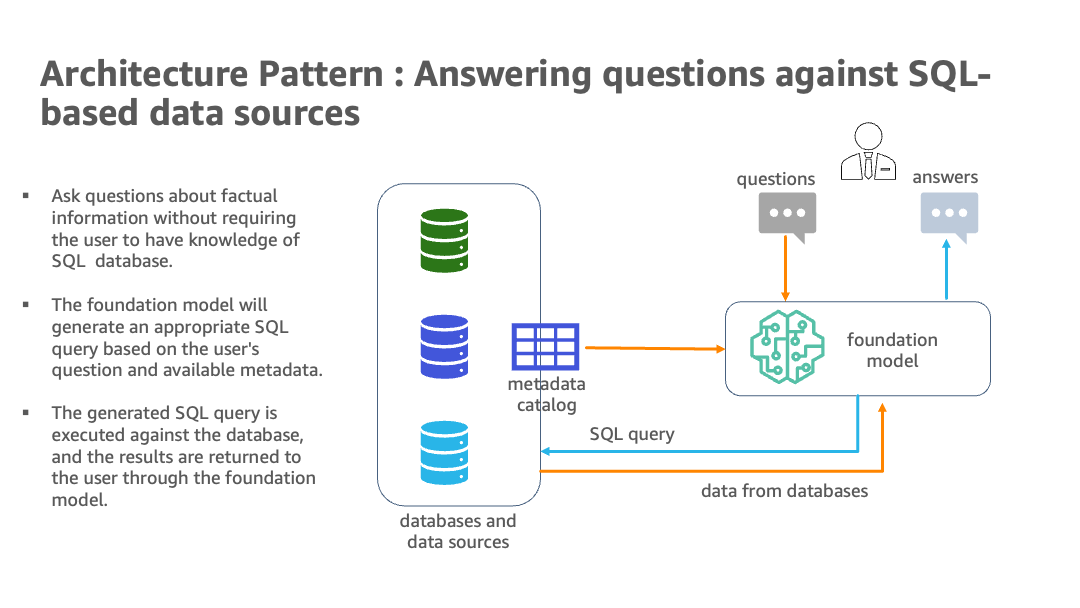
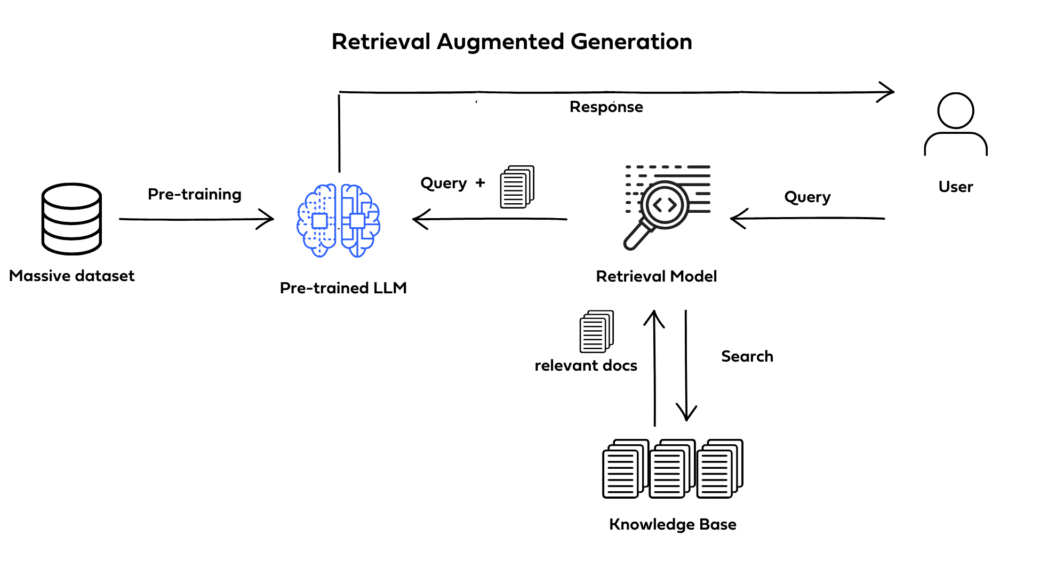
RAG architectures enhance Generative AI by providing it with access to external knowledge sources, such as PDF documents. Instead of relying solely on its pre-trained knowledge, the model can retrieve relevant information from these documents and use it to generate more accurate and contextually appropriate responses.
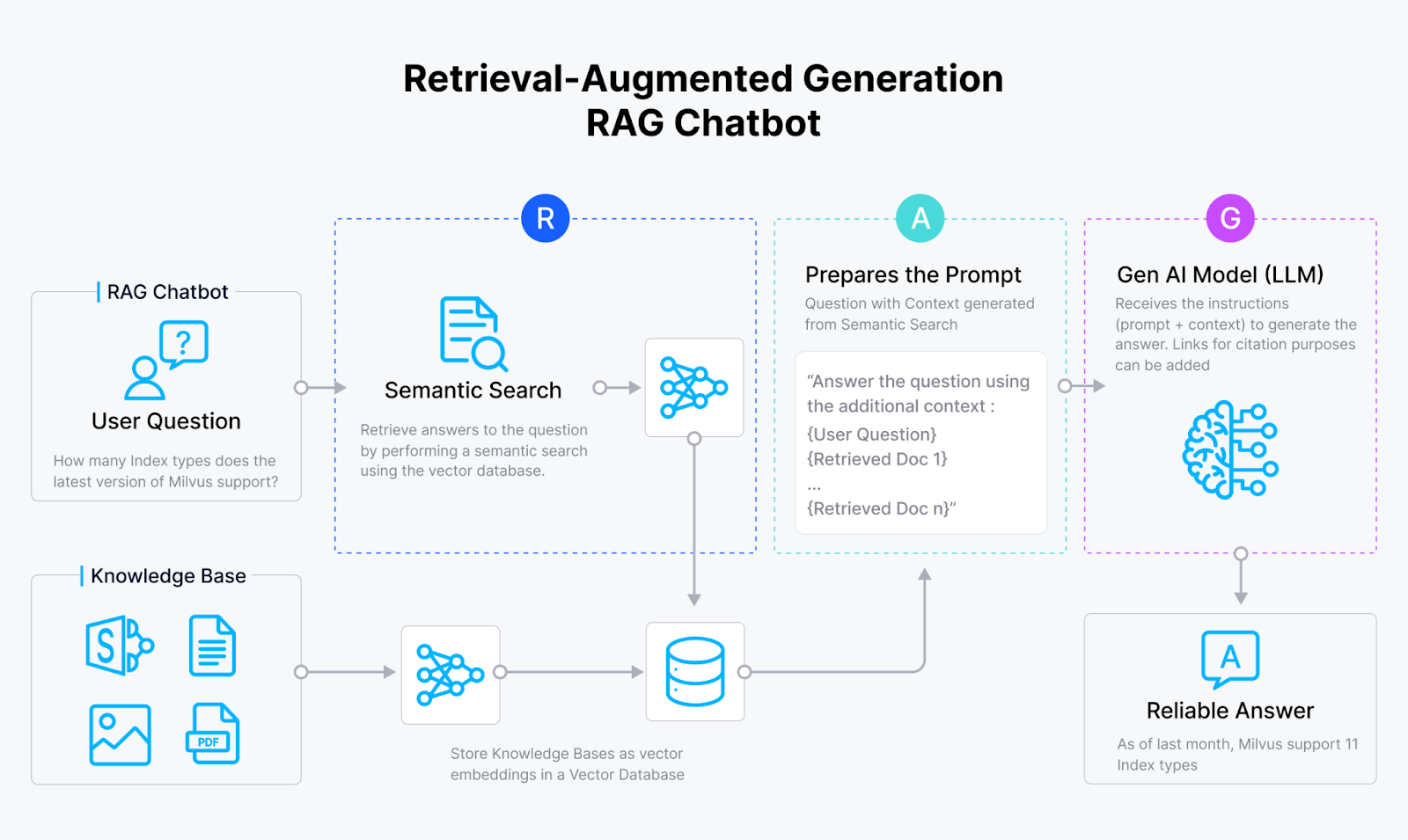
How RAG Works with PDFs
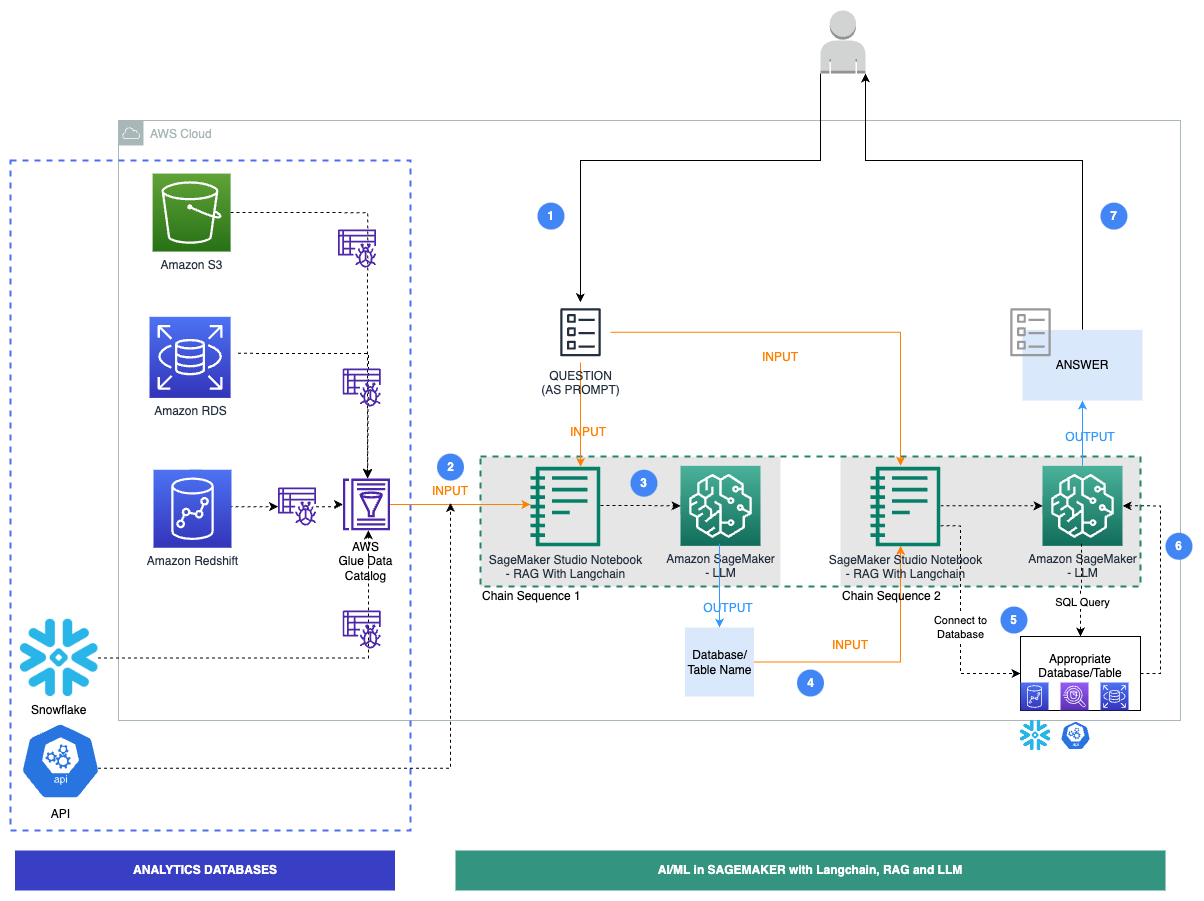
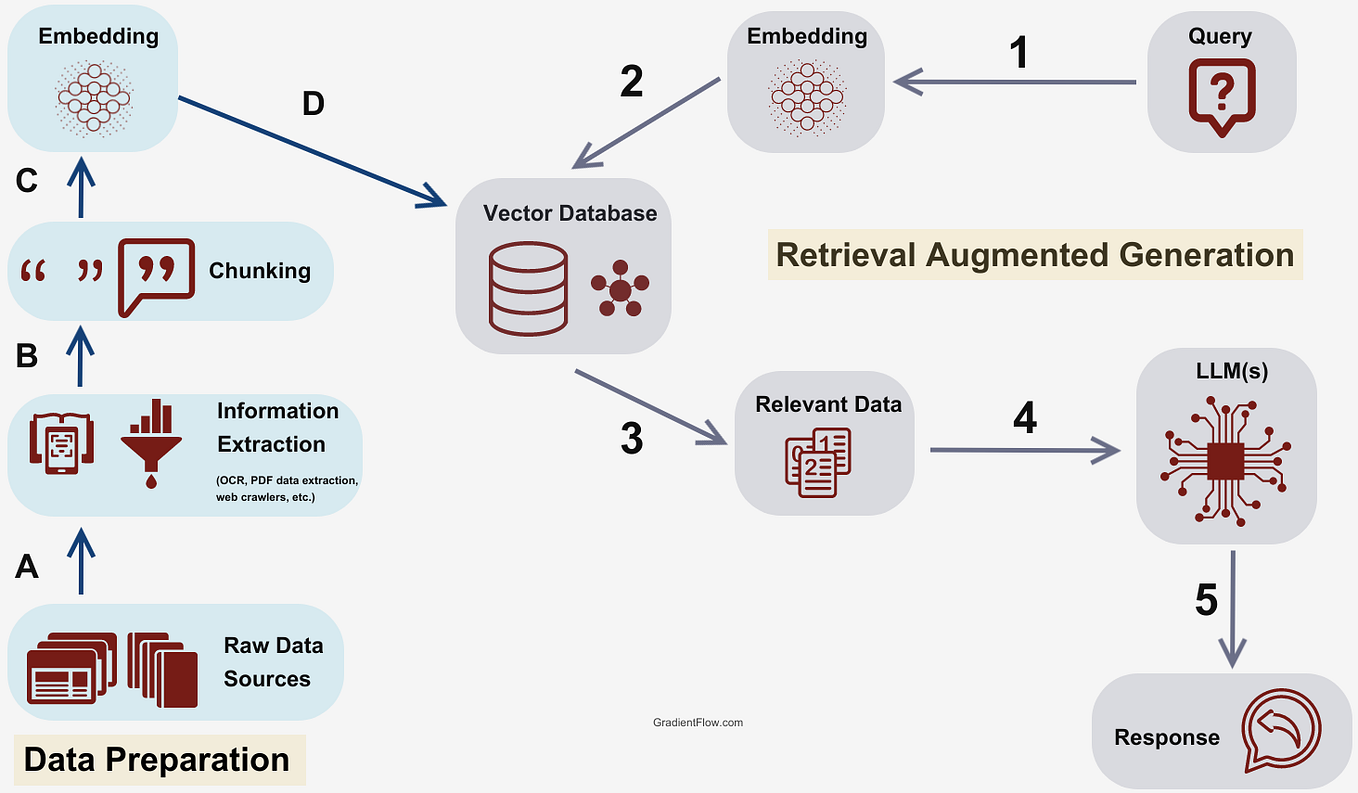
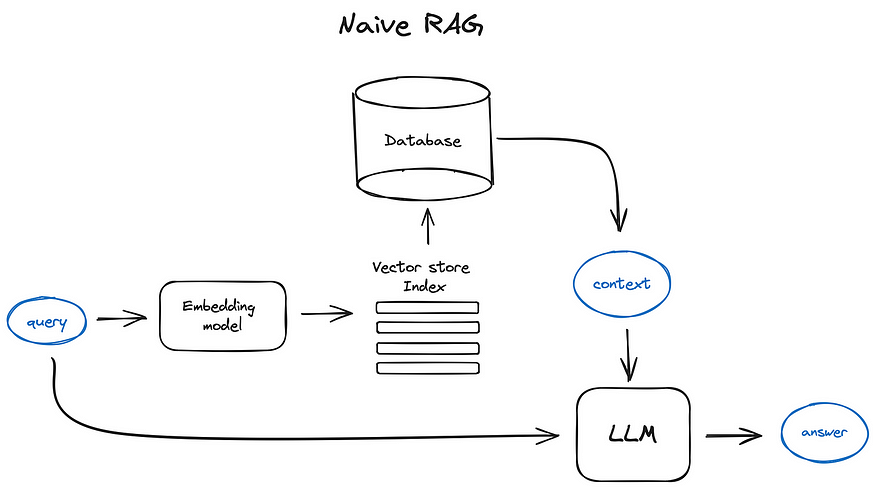
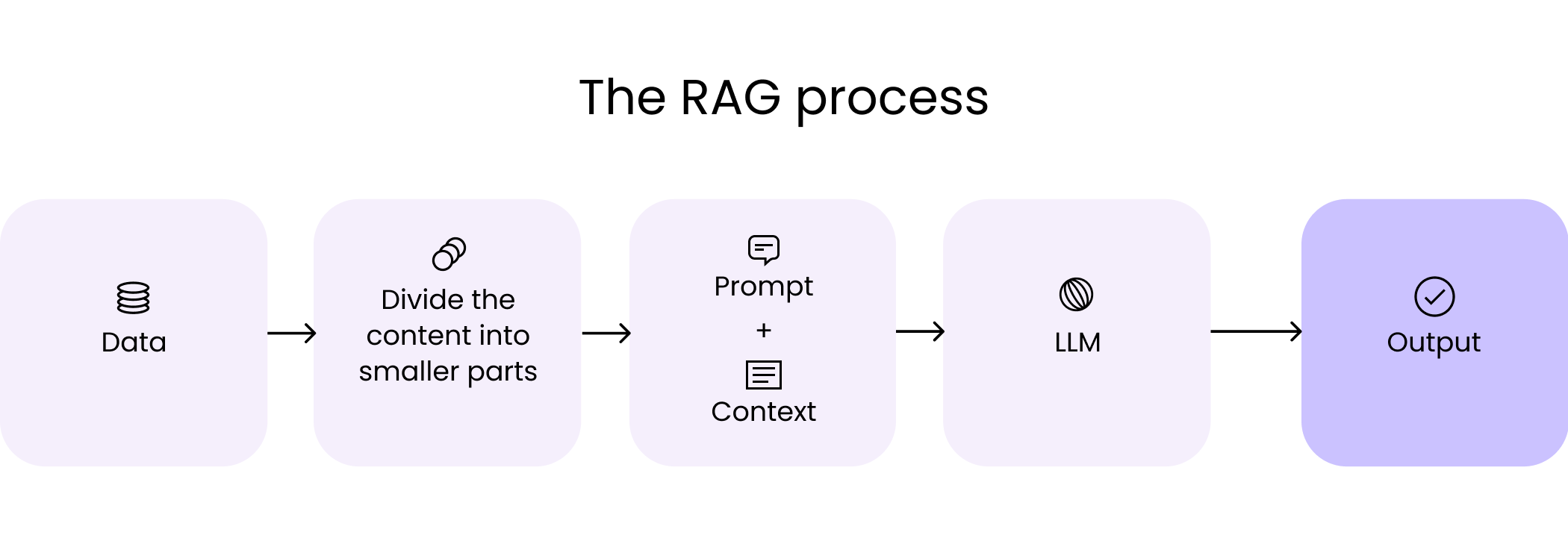
The RAG process typically involves several key steps when dealing with PDF data. First, the PDF document is processed to extract the text content, which often involves overcoming challenges like complex layouts and embedded images.
Next, the extracted text is chunked into smaller segments and converted into numerical representations called embeddings, using models like Sentence Transformers. These embeddings capture the semantic meaning of the text.
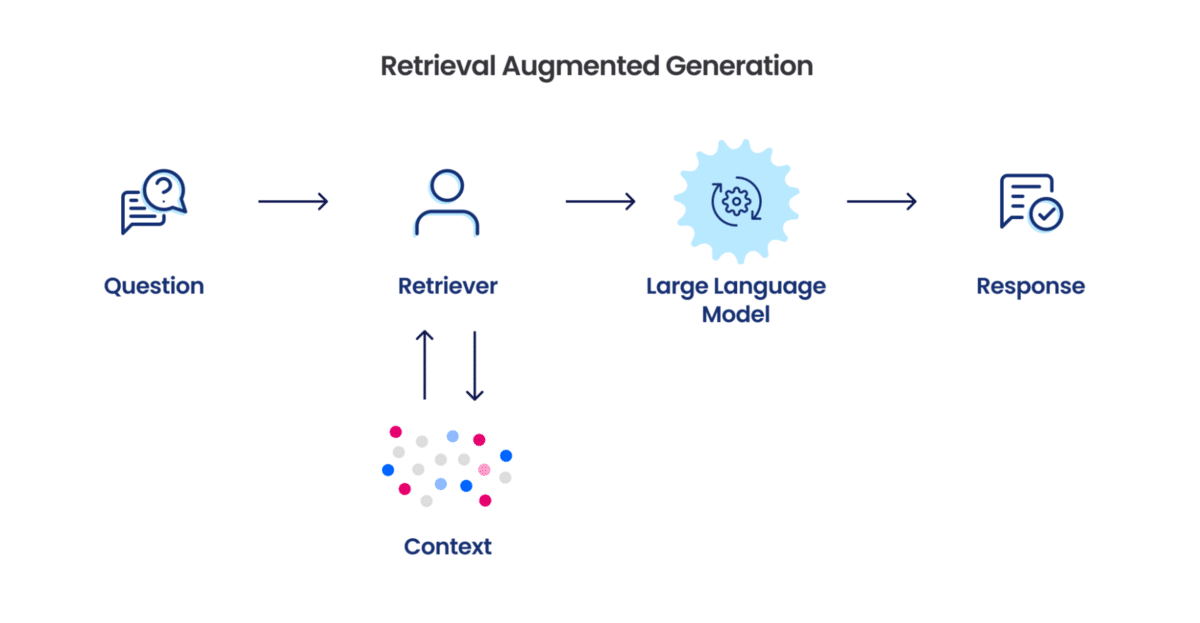
When a user asks a question, the query is also converted into an embedding, and a similarity search is performed against the document embeddings. The most relevant chunks of text are retrieved and fed into the Generative AI model along with the original question.
Finally, the Generative AI model synthesizes the retrieved information and generates a comprehensive and informative response. This allows users to effectively query and extract insights from PDF documents without manually searching through them.
Real-World Applications Across Industries
The combination of Generative AI and RAG is transforming various industries by enabling them to unlock the value of their PDF data. In the legal sector, for example, lawyers can quickly analyze case files, contracts, and regulations to find relevant precedents and support their arguments.
According to a recent report by LexisNexis, legal professionals who utilize AI-powered research tools reported a 30% increase in efficiency. This translates to significant cost savings and improved client service.
In the healthcare industry, researchers can analyze scientific papers, clinical trial reports, and patient records to identify trends, discover new treatments, and improve patient outcomes. The National Institutes of Health (NIH) are actively exploring the use of AI to accelerate medical research.
Financial institutions are leveraging RAG to extract insights from financial reports, market analysis documents, and regulatory filings. This helps them make informed investment decisions, manage risk, and comply with regulations.
Customer service departments are using RAG to create intelligent chatbots that can answer customer questions based on information stored in product manuals, FAQs, and internal knowledge bases. This improves customer satisfaction and reduces the workload on human agents.
Challenges and Considerations
While the potential of Generative AI and RAG for PDF data is immense, there are also several challenges and considerations that need to be addressed. One of the main challenges is ensuring the accuracy and reliability of the generated responses.
Generative AI models can sometimes hallucinate or generate incorrect information, especially when dealing with complex or ambiguous data. It is crucial to implement robust validation and verification mechanisms to prevent the spread of misinformation.
Another challenge is dealing with sensitive or confidential information. It is important to implement appropriate data security and privacy measures to protect sensitive data from unauthorized access or disclosure.
The European Union's General Data Protection Regulation (GDPR) and other data privacy laws impose strict requirements on the processing of personal data, which must be carefully considered when using AI to analyze PDF documents.
Furthermore, bias in the training data can lead to biased or unfair outcomes. It is important to carefully curate and pre-process the data to mitigate bias and ensure fairness.
The Future of Data Unlocking
The future of data unlocking with Generative AI and RAG looks promising. As these technologies continue to evolve, we can expect to see even more sophisticated and powerful applications emerge.
One trend to watch is the development of more specialized models that are tailored to specific industries and use cases. These models will be trained on domain-specific data, enabling them to generate more accurate and relevant responses.
Another trend is the integration of RAG with other AI technologies, such as computer vision and natural language processing, to create more comprehensive and intelligent data analysis solutions. This will enable users to extract insights from a wider range of data sources, including images, videos, and audio recordings.
According to a Gartner report, the market for AI-powered knowledge management solutions is expected to grow significantly in the coming years, driven by the increasing demand for data-driven decision-making and improved efficiency.
The convergence of Generative AI and RAG is revolutionizing how we interact with and extract value from unstructured data, particularly PDFs. By addressing the challenges and embracing the opportunities, organizations can unlock the full potential of their data and gain a significant competitive advantage in the years to come. The ability to query, analyze, and synthesize information locked within these documents is no longer a futuristic vision, but a present-day reality.