Which Of The Following Occurs During Data Cleansing
In the ever-evolving landscape of data management, ensuring data quality is paramount. Data cleansing, a critical step in preparing data for analysis and decision-making, involves a variety of processes designed to identify and correct errors. But what exactly occurs during this vital stage?
This article explores the key activities performed during data cleansing, offering insights into how organizations strive to maintain accurate and reliable datasets. Understanding these processes is crucial for anyone involved in data analysis, business intelligence, or data-driven decision-making.
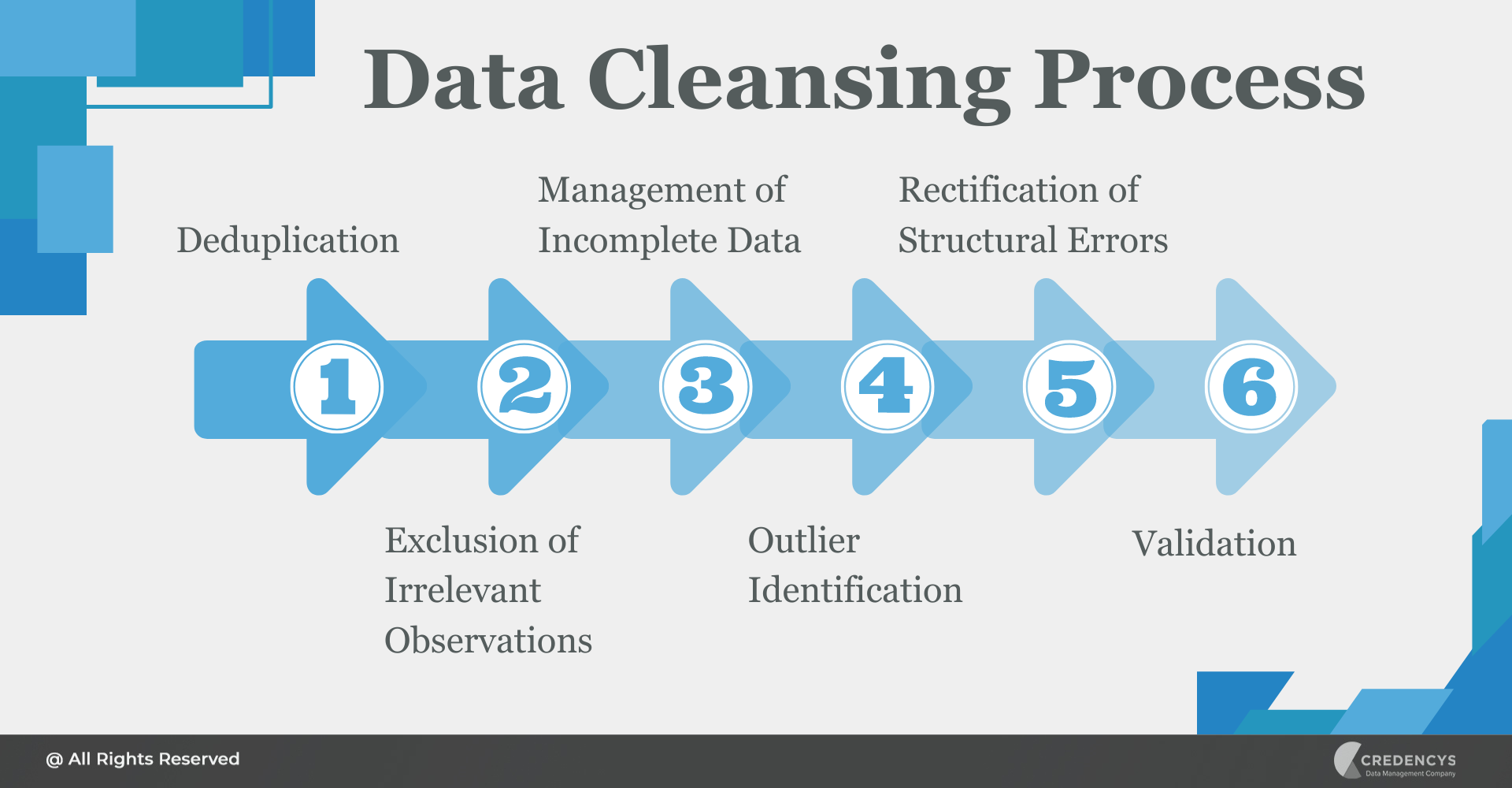
Identifying Inaccuracies: The First Step
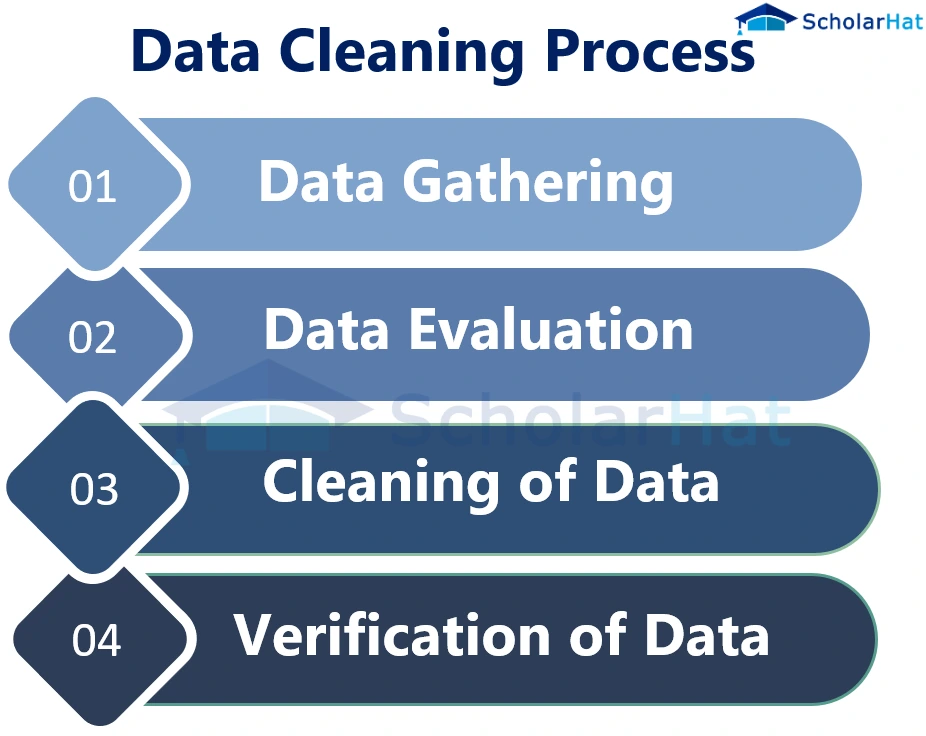
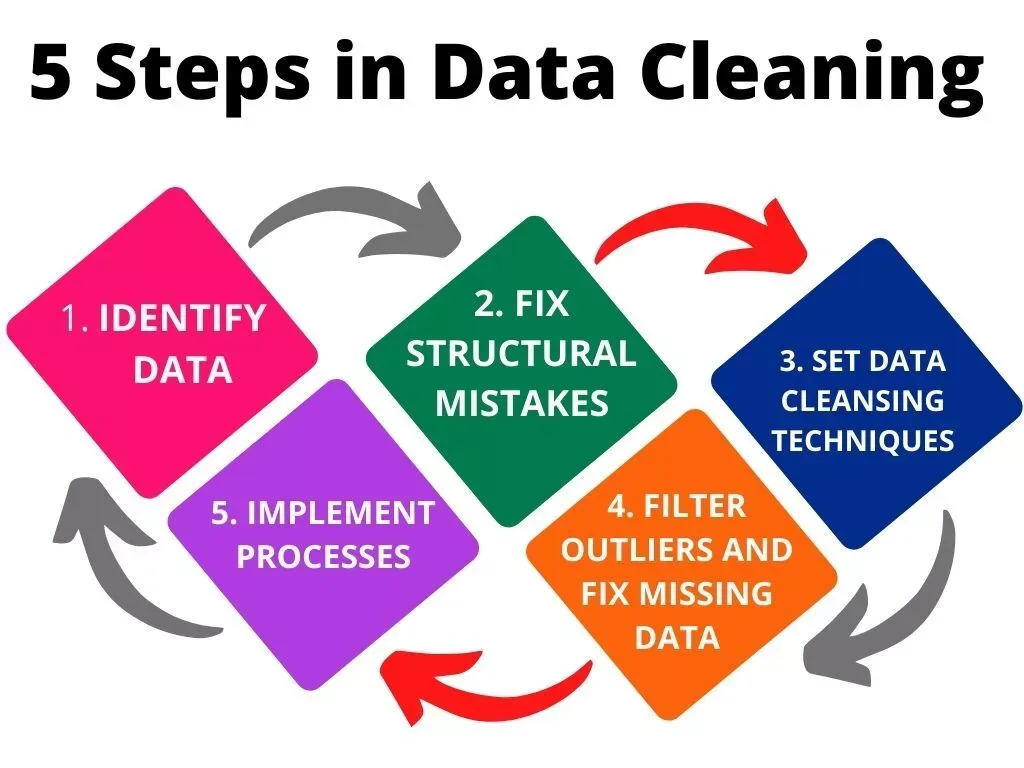
The initial phase of data cleansing focuses on identifying errors and inconsistencies. This often involves utilizing both manual and automated techniques to assess the data's integrity. Tools for profiling data are employed to reveal patterns, anomalies, and potential issues within the dataset.
According to a report by Gartner, data profiling tools can help identify up to 80% of data quality issues. This process allows data professionals to understand the characteristics of the data, including data types, value ranges, and missing values.
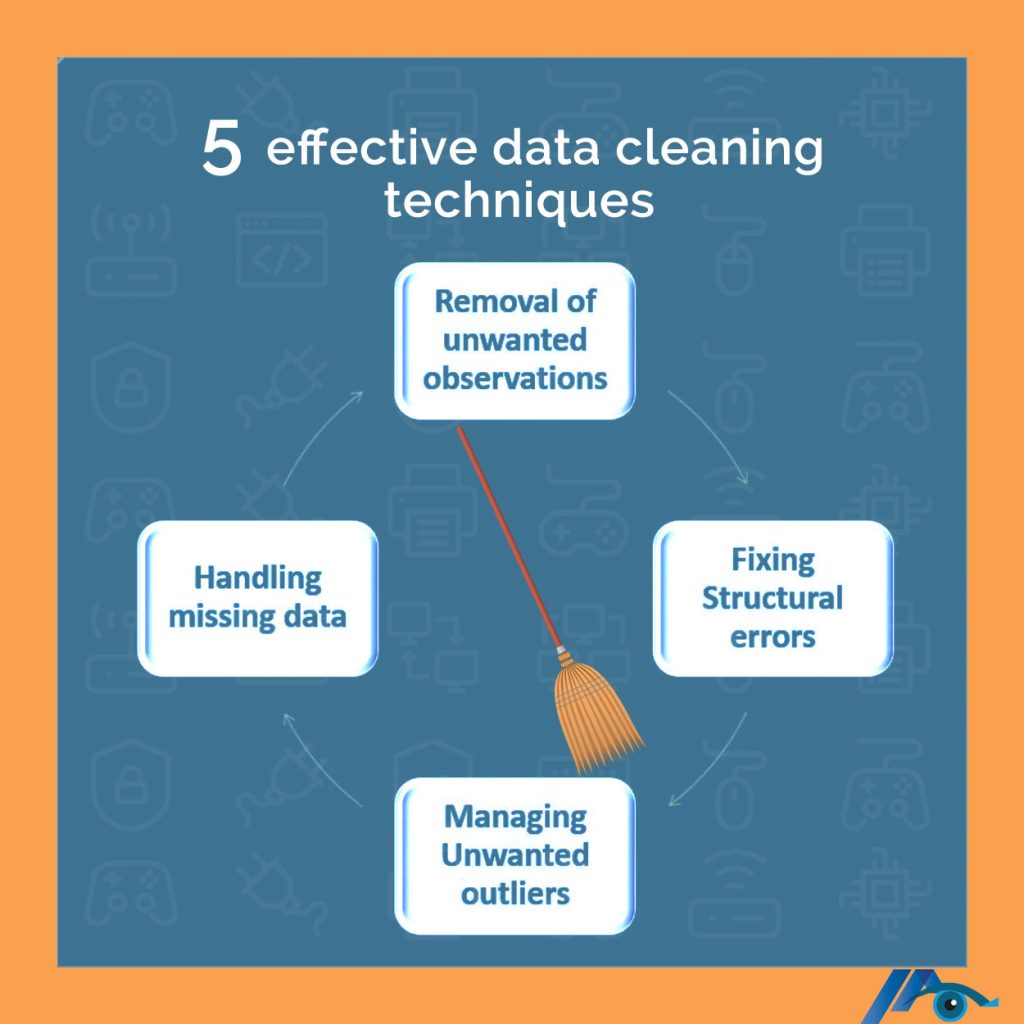
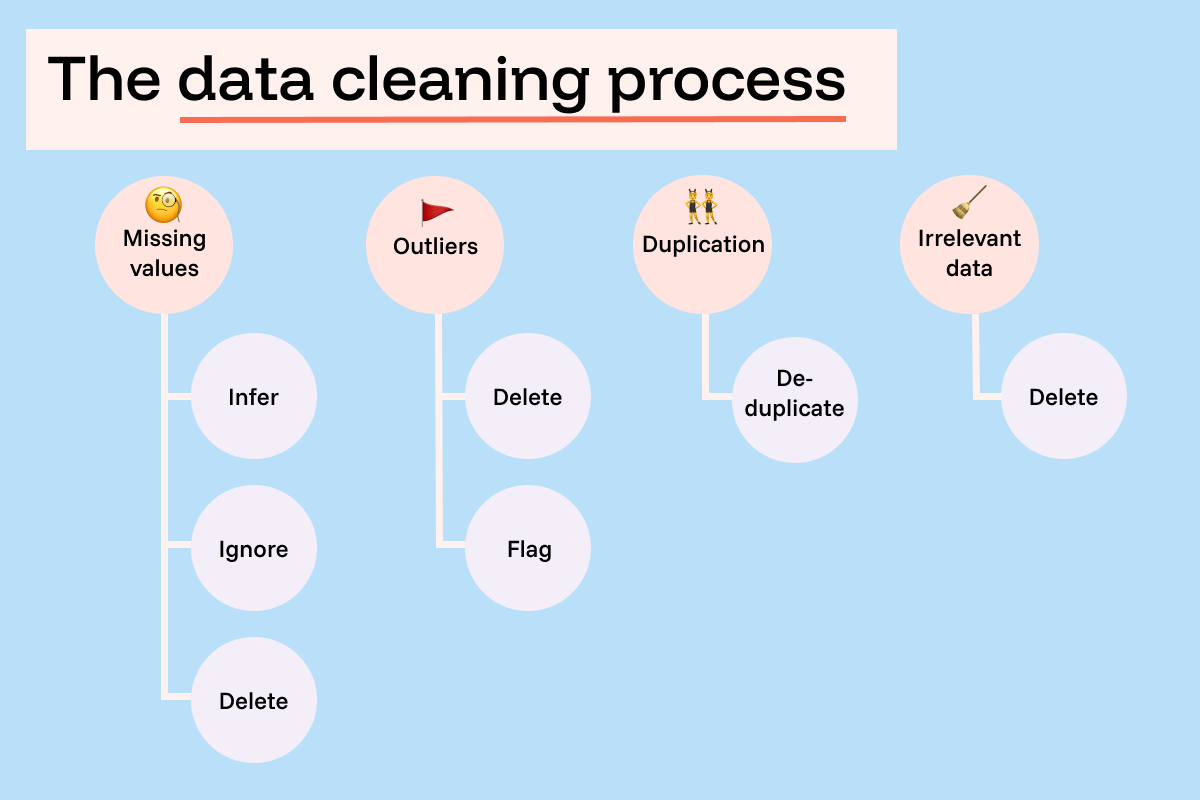
Missing Value Imputation
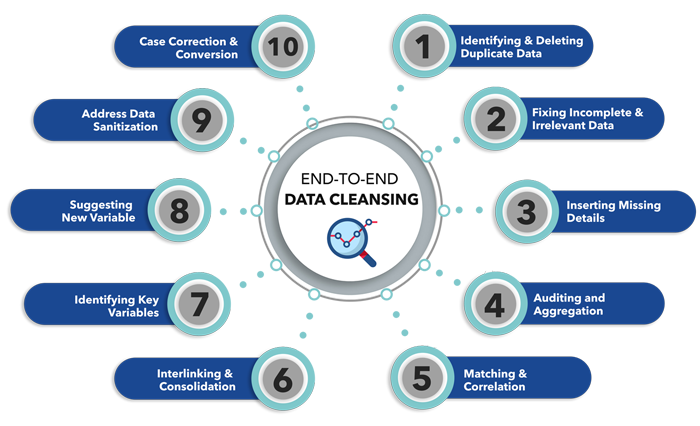
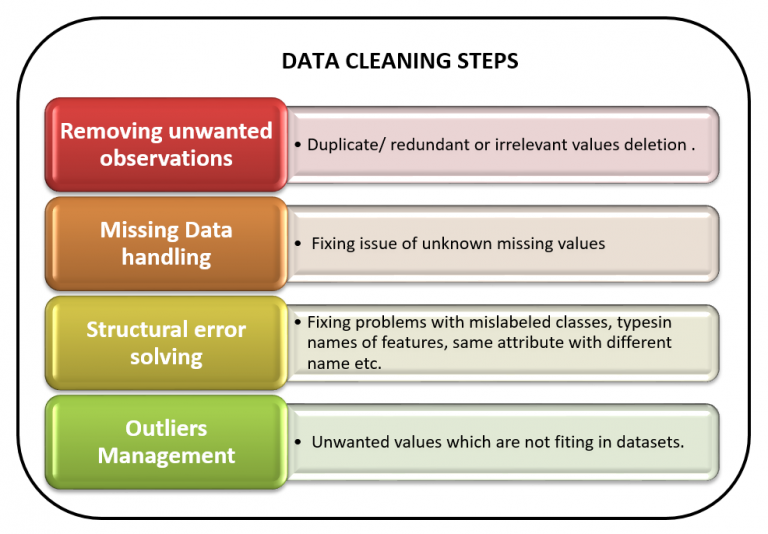
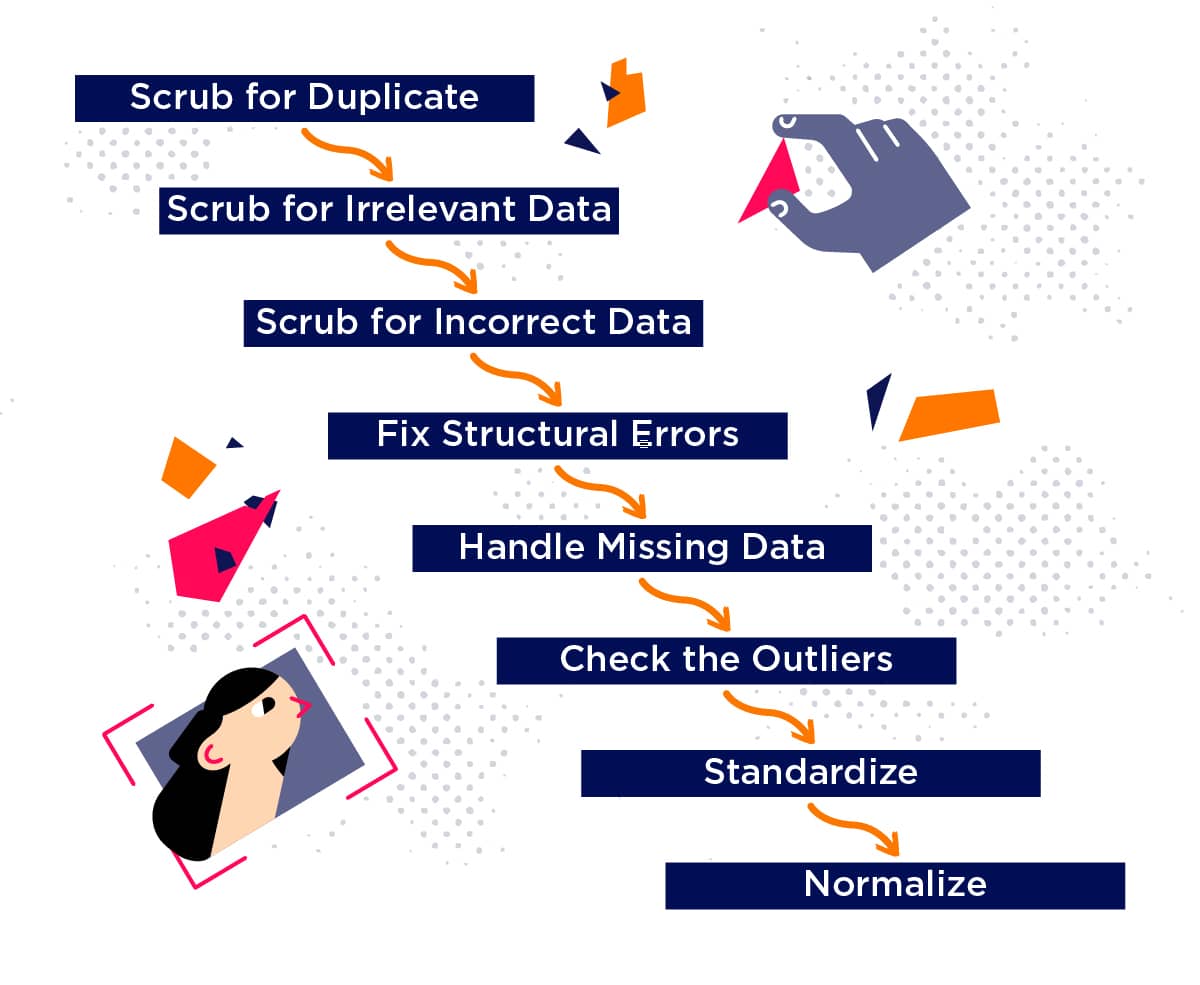
One of the most common issues encountered during data cleansing is missing data. Addressing these gaps is critical for ensuring the completeness and reliability of the dataset. Imputation techniques, such as replacing missing values with the mean, median, or mode, are frequently used.
More sophisticated methods involve using machine learning algorithms to predict missing values based on other variables. However, it’s crucial to document the imputation method used, as imputation can introduce bias if not carefully considered.
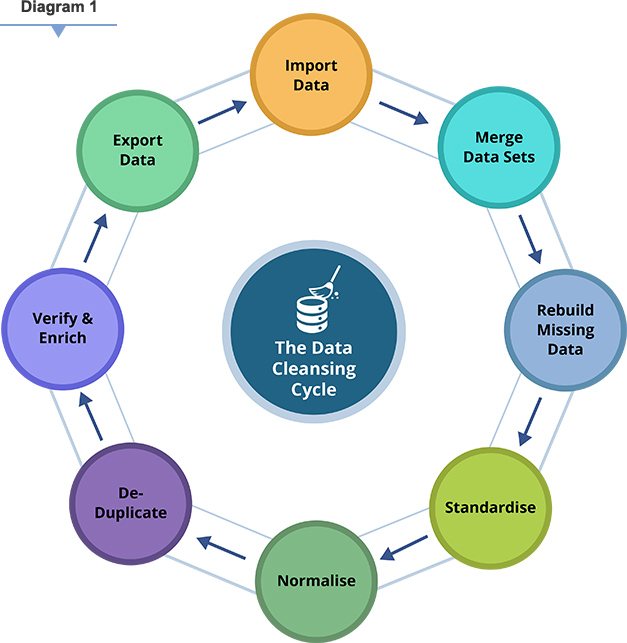
Removing Duplicates
Duplicate entries can skew analyses and lead to inaccurate insights. Therefore, identifying and removing duplicate records is another essential task in data cleansing. This process often involves comparing records based on key fields to identify potential duplicates.
Different strategies can be used to handle duplicates, such as merging the information from the duplicate records into a single record or deleting the redundant entries. The specific approach will depend on the nature of the data and the goals of the analysis.
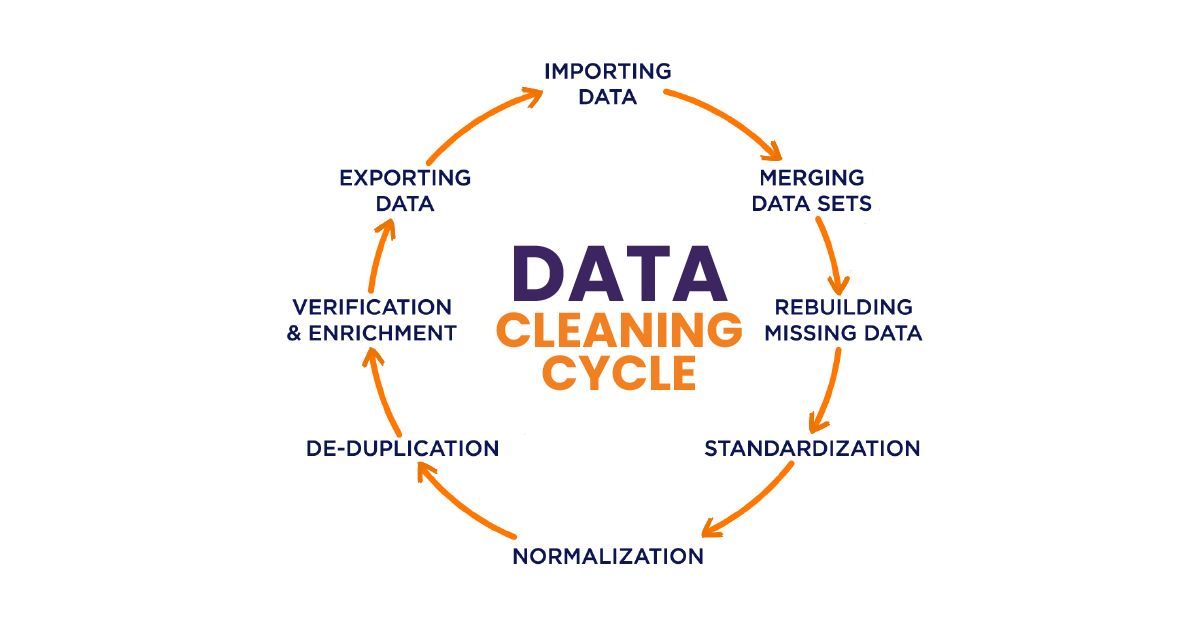
Standardizing and Formatting Data
Data often originates from various sources, resulting in inconsistencies in formatting and data types. Standardizing and formatting data is essential for ensuring consistency and enabling effective data integration.
This involves converting data to a uniform format, such as standardizing date formats or converting all text to lowercase. Standardizing data ensures that it can be properly processed and analyzed by downstream systems.
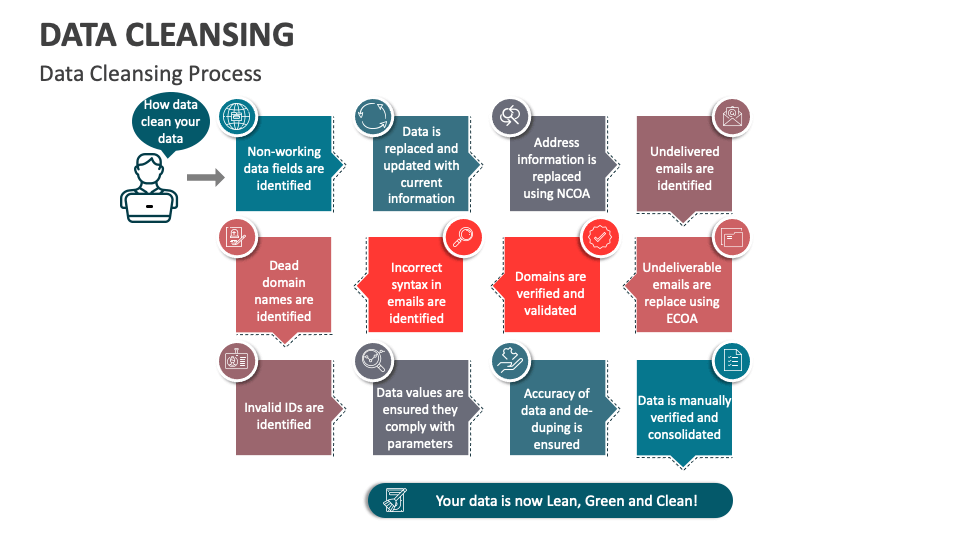
Correcting Data Errors
Human error and system glitches can lead to inaccuracies in data. Correcting these errors is a vital part of the data cleansing process. This may involve manually correcting typos, resolving inconsistencies, or verifying data against external sources.
For example, if an address is entered incorrectly, it may be verified using address validation services. Similarly, customer contact information may be verified against telephone directories or other databases.
Data Validation and Verification
Data validation involves checking the data against predefined rules and constraints to ensure its accuracy and consistency. Verification processes confirm that the data meets specific quality standards.
This can include validating data types, verifying that values fall within acceptable ranges, and ensuring that data conforms to established formats. Data validation rules can be implemented using data quality tools or programming scripts.
Resolving Data Conflicts
Data conflicts arise when the same information is represented differently in different sources. Resolving these conflicts is a crucial step in ensuring data consistency. This may involve establishing a single source of truth or implementing rules to prioritize data from different sources.
Data governance policies play a vital role in defining how data conflicts are resolved and ensuring that the correct data is used for analysis. Data conflict resolution can involve collaboration between data stewards and subject matter experts.
The Impact of Effective Data Cleansing
Effective data cleansing has a significant impact on the accuracy and reliability of data analysis. Clean data leads to better insights, improved decision-making, and enhanced business outcomes. Organizations that invest in data cleansing are better positioned to leverage their data assets for competitive advantage.
According to research conducted by MIT Sloan Management Review, organizations with high-quality data are 35% more likely to report successful business outcomes. This underscores the importance of data cleansing as a foundational element of data-driven decision-making.
In conclusion, data cleansing encompasses a range of activities, including identifying inaccuracies, removing duplicates, standardizing formats, correcting errors, and validating data. These processes are essential for ensuring that data is accurate, consistent, and reliable, ultimately enabling organizations to make informed decisions and achieve their business objectives. Ignoring these steps can lead to costly mistakes and missed opportunities.