Which Of These Statements About Availability Zones Is Not True
The relentless pursuit of uptime has driven cloud computing to architecturally complex solutions. At the heart of this architecture lie Availability Zones (AZs), designed to mitigate failures and ensure business continuity. However, a critical examination reveals misconceptions abound, leading to potentially flawed deployment strategies and a false sense of security.
This article dissects common understandings of AZs, identifying a crucial point of contention: the presumption of absolute independence and zero latency between them. We delve into the realities of shared infrastructure, network dependencies, and the subtle but impactful compromises inherent in AZ deployments, aiming to equip readers with a more nuanced understanding of their limitations and capabilities. Ignoring these nuances can lead to costly architectural mistakes and, ironically, reduced availability.
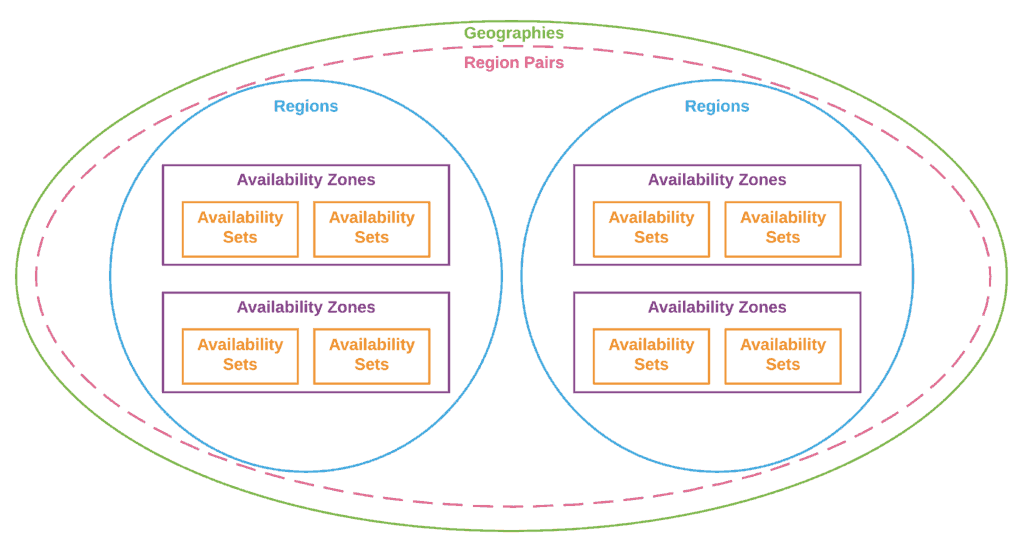
Understanding Availability Zones: The Basics
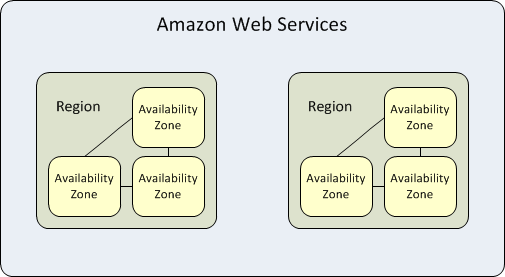
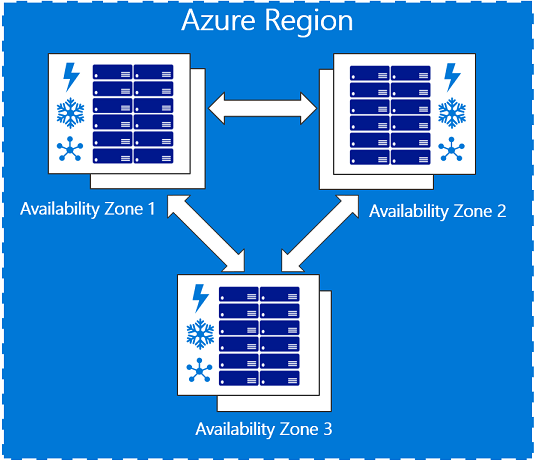
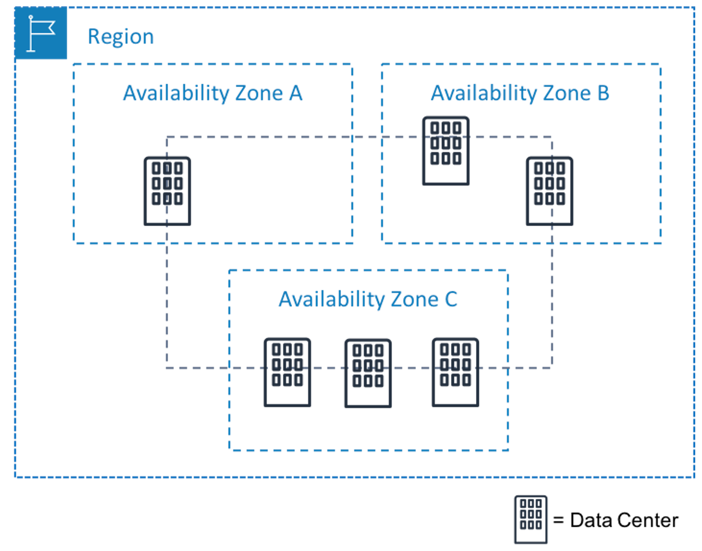
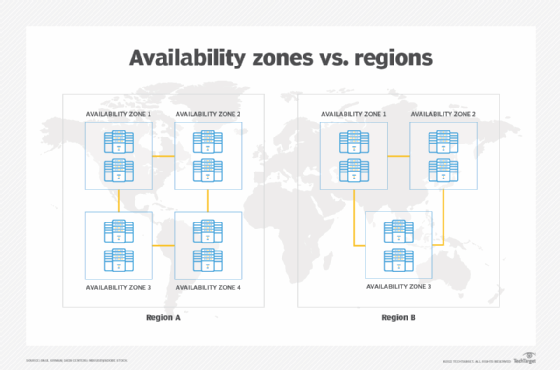
Availability Zones are physically separate locations within a cloud region. They are designed to be isolated from failures in other AZs, providing fault tolerance. This separation typically includes independent power, networking, and cooling infrastructure.
The core principle is that if one AZ experiences an outage, applications can continue to run in other AZs within the same region. This is a key component of a highly available and resilient cloud architecture.
The Myth of Complete Independence
While AZs are designed to be isolated, complete independence is a practical impossibility. Shared infrastructure, albeit minimized, often exists at the regional level.
For example, control planes and management services are frequently regional and can impact all AZs within that region. This means a failure in the regional control plane can disrupt operations across multiple AZs, even if the AZs themselves are healthy.
Furthermore, the physical proximity of AZs within a region implies a degree of shared risk. Natural disasters, widespread power outages, or even geographically localized network disruptions can affect multiple AZs simultaneously.
The Latency Factor
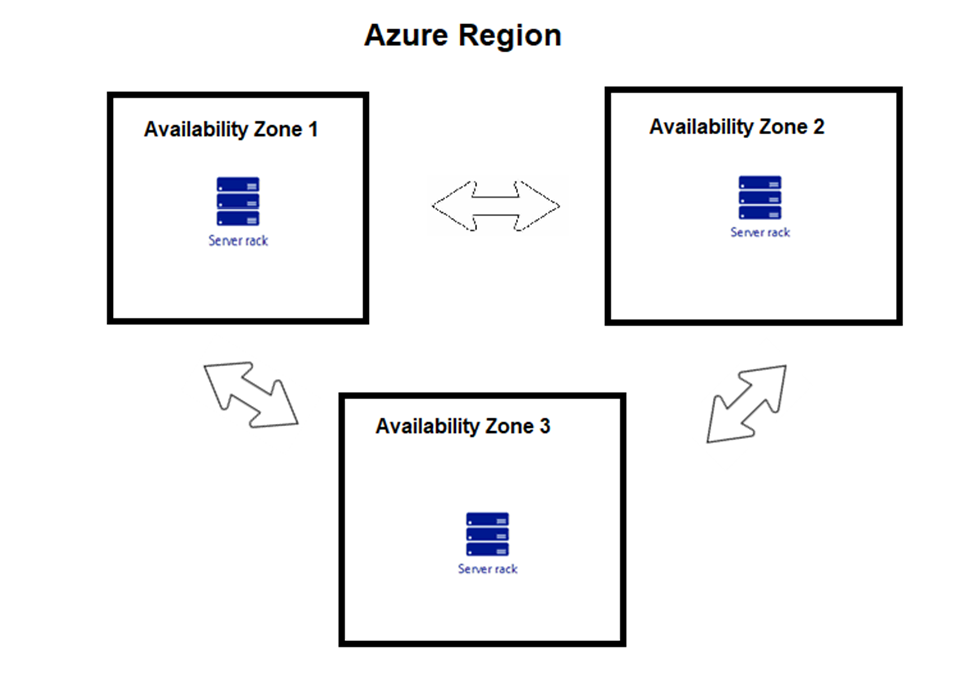
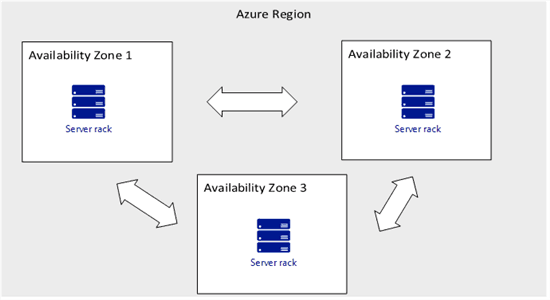
One of the most prevalent misconceptions is the assumption of negligible latency between AZs. While cloud providers strive to minimize latency, it is inherently non-zero.
The distance between AZs, while often within a few kilometers, introduces latency due to the speed of light and network infrastructure. This latency can be significant for latency-sensitive applications, impacting performance and user experience.
Furthermore, network congestion and routing issues can further exacerbate latency between AZs. This can lead to unpredictable performance and potential disruptions in application functionality.
Debunking the Statement: The Untruth About Availability Zones
The statement "Availability Zones are guaranteed to have zero latency between them" is demonstrably false. Network latency, however small, always exists due to physical distance and network infrastructure. This seemingly minor detail is crucial for application design and deployment.
Ignoring this latency can lead to suboptimal application architectures, performance bottlenecks, and increased costs. Properly accounting for latency is essential for building truly resilient and high-performing cloud applications.
Shared Fate and Regional Events
Despite the isolation efforts, AZs within a region are still susceptible to shared fate scenarios. These scenarios involve events that impact multiple AZs simultaneously.
Examples include widespread power outages affecting the entire region, large-scale network disruptions, or coordinated cyberattacks targeting the regional infrastructure. While rare, these events can compromise the availability of applications even when deployed across multiple AZs.
Therefore, relying solely on AZ-level redundancy is insufficient for achieving true resilience. Organizations must also consider regional-level mitigation strategies, such as multi-region deployments or robust backup and disaster recovery plans.
Multi-Region Deployments: The Next Level of Resilience
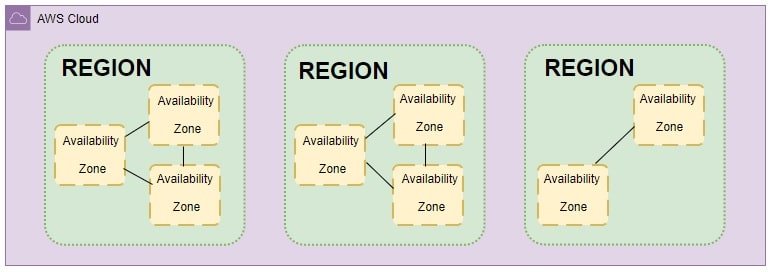
To mitigate the risk of regional failures, organizations increasingly adopt multi-region deployment strategies. This involves deploying applications across multiple geographically distinct regions.
Multi-region deployments provide a higher level of fault tolerance and resilience compared to single-region deployments with multiple AZs. In the event of a regional outage, applications can fail over to another region with minimal disruption.
However, multi-region deployments also introduce increased complexity and cost. Careful planning and implementation are essential to ensure seamless failover and data consistency across regions.
Best Practices for Availability Zone Deployment
To maximize the benefits of AZs and minimize the risks, organizations should adhere to several best practices. Distribute application components across multiple AZs to achieve fault tolerance.
Regularly test failover procedures to ensure that applications can seamlessly transition to other AZs in the event of an outage. Implement robust monitoring and alerting systems to detect and respond to potential issues proactively.
Consider latency requirements when designing application architectures and choose AZs that minimize latency for critical components. Regularly review and update disaster recovery plans to address potential regional-level failures.
The Future of Availability Zones
Cloud providers are continuously investing in improving the resilience and isolation of AZs. Future advancements may include enhanced network isolation, improved power redundancy, and more sophisticated failure detection mechanisms.
However, the fundamental limitations of physical proximity and shared infrastructure will likely remain. Organizations must therefore continue to adopt a holistic approach to resilience, combining AZ-level redundancy with regional and multi-regional strategies.
The key takeaway is that understanding the limitations of Availability Zones is just as important as understanding their capabilities. A nuanced and informed approach to cloud architecture is essential for building truly resilient and highly available applications.